Entailment Models¶
Entailment models take two sequences of text as input and make a classification decision on the pair. Typically that decision represents whether one sentence entails the other, but we’ll use this family of models to represent any kind of classification decision over pairs of text.
Inputs: Two text sequences
Output: Some classification decision (typically “entails/not entails”, “entails/neutral/contradicts”, or similar)
DecomposableAttention¶
-
class
deep_qa.models.entailment.decomposable_attention.DecomposableAttention(params: deep_qa.common.params.Params)[source]¶ Bases:
deep_qa.training.text_trainer.TextTrainerThis
TextTrainerimplements the Decomposable Attention model described in “A Decomposable Attention Model for Natural Language Inference”, by Parikh et al., 2016, with some optional enhancements before the decomposable attention actually happens. Specifically, Parikh’s original model took plain word embeddings as input to the decomposable attention; we allow other operations the transform these word embeddings, such as running a biLSTM on them, before running the decomposable attention layer.Inputs:
- A “text” sentence, with shape (batch_size, sentence_length)
- A “hypothesis” sentence, with shape (batch_size, sentence_length)
Outputs:
- An entailment decision per input text/hypothesis pair, in {entails, contradicts, neutral}.
Parameters: num_seq2seq_layers : int, optional (default=0)
After getting a word embedding, how many stacked seq2seq encoders should we use before doing the decomposable attention? The default of 0 recreates the original decomposable attention model.
share_encoders : bool, optional (default=True)
Should we use the same seq2seq encoder for the text and hypothesis, or different ones?
decomposable_attention_params : Dict[str, Any], optional (default={})
These parameters get passed to the
DecomposableAttentionEntailmentlayer object, and control things like the number of output labels, number of hidden layers in the entailment MLPs, etc. See that class for a complete description of options here.-
_build_model()[source]¶ Constructs and returns a DeepQaModel (which is a wrapper around a Keras Model) that will take the output of self._get_training_data as input, and produce as output a true/false decision for each input. Note that in the multiple gpu case, this function will be called multiple times for the different GPUs. As such, you should be wary of this function having side effects unrelated to building a computation graph.
The returned model will be used to call model.fit(train_input, train_labels).
-
_instance_type()[source]¶ When reading datasets, what
Instancetype should we create? TheInstanceclass contains code that creates actual numpy arrays, so this instance type determines the inputs that you will get to your model, and the outputs that are used for training.
-
_set_padding_lengths_from_model()[source]¶ This gets called when loading a saved model. It is analogous to
_set_padding_lengths, but needs to set all of the values set in that method just by inspecting the loaded model. If we didn’t have this, we would not be able to correctly pad data after loading a model.
-
get_padding_memory_scaling(padding_lengths: typing.Dict[str, int]) → int[source]¶ This method is for computing adaptive batch sizes. We assume that memory usage is a function that looks like this:
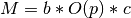 , where
, where 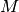 is the memory
usage,
is the memory
usage, 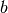 is the batch size,
is the batch size,  is some constant that depends on how much GPU
memory you have and various model hyperparameters, and
is some constant that depends on how much GPU
memory you have and various model hyperparameters, and 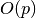 is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set
is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set 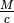 using the
using the
adaptive_memory_usage_constantparameter inDataGenerator. The model (this method) specifies, so we can solve for the batch size . The more
specific you get in specifying in this function, the better a job we can do in
optimizing memory usage.Parameters: padding_lengths: Dict[str, int]
Dictionary containing padding lengths, mapping keys like
num_sentence_wordsto ints. This method computes a function of these ints.Returns: O(p): int
The big-O complexity of the model, evaluated with the specific ints given in
padding_lengthsdictionary.