Reading Comprehension¶
AttentionSumReader¶
-
class
deep_qa.models.reading_comprehension.attention_sum_reader.AttentionSumReader(params: deep_qa.common.params.Params)[source]¶ Bases:
deep_qa.training.text_trainer.TextTrainerThis TextTrainer implements the Attention Sum Reader model described by Kadlec et. al 2016. It takes a question and document as input, encodes the document and question words with two separate Bidirectional GRUs, and then takes the dot product of the question embedding with the document embedding of each word in the document. This creates an attention over words in the document, and it then selects the option with the highest summed or mean weight as the answer.
-
_build_model()[source]¶ The basic outline here is that we’ll pass the questions and the document / passage (think of this as a collection of possible answer choices) into a word embedding layer.
Then, we run the word embeddings from the document (a sequence) through a bidirectional GRU and output a sequence that is the same length as the input sequence size. For each time step, the output item (“contextual embedding”) is the concatenation of the forward and backward hidden states in the bidirectional GRU encoder at that time step.
To get the encoded question, we pass the words of the question into another bidirectional GRU. This time, the output encoding is a vector containing the concatenation of the last hidden state in the forward network with the last hidden state of the backward network.
We then take the dot product of the question embedding with each of the contextual embeddings for the words in the documents. We sum up all the occurences of a word (“total attention”), and pick the word with the highest total attention in the document as the answer.
-
_set_padding_lengths(padding_lengths: typing.Dict[str, int])[source]¶ Set the padding lengths of the model.
-
_set_padding_lengths_from_model()[source]¶ This gets called when loading a saved model. It is analogous to
_set_padding_lengths, but needs to set all of the values set in that method just by inspecting the loaded model. If we didn’t have this, we would not be able to correctly pad data after loading a model.
-
BidirectionalAttentionFlow¶
-
class
deep_qa.models.reading_comprehension.bidirectional_attention.BidirectionalAttentionFlow(params: deep_qa.common.params.Params)[source]¶ Bases:
deep_qa.training.text_trainer.TextTrainerThis class implements Minjoon Seo’s Bidirectional Attention Flow model for answering reading comprehension questions (ICLR 2017).
The basic layout is pretty simple: encode words as a combination of word embeddings and a character-level encoder, pass the word representations through a bi-LSTM/GRU, use a matrix of attentions to put question information into the passage word representations (this is the only part that is at all non-standard), pass this through another few layers of bi-LSTMs/GRUs, and do a softmax over span start and span end.
Parameters: num_hidden_seq2seq_layers : int, optional (default:
2)At the end of the model, we add a few stacked biLSTMs (or similar), to give the model some depth. This parameter controls how many deep layers we should use.
num_passage_words : int, optional (default:
None)If set, we will truncate (or pad) all passages to this length. If not set, we will pad all passages to be the same length as the longest passage in the data.
num_question_words : int, optional (default:
None)Same as
num_passage_words, but for the number of words in the question. (default:None)num_highway_layers : int, optional (default:
2)After constructing a word embedding, but before the first biLSTM layer, Min has some
Highwaylayers operating on the word embedding layer. This parameter specifies how many of those to do. (default:2)highway_activation : string, optional (default:
'relu')Specifies the activation function to use for the
Highwaylayers mentioned above. Any Keras activation function is acceptable here.similarity_function : Dict[str, Any], optional (default:
{'type': 'linear', 'combination': 'x,y,x*y'})Specifies the similarity function to use when computing a similarity matrix between question words and passage words. By default we use the function Min used in his paper.
Notes
Min’s code uses tensors of shape
(batch_size, num_sentences, sentence_length)to represent the passage, splitting it up into sentences, where here we just have one long passage sequence. I was originally afraid this might mean he applied the biLSTM on each sentence independently, but it looks like he flattens it to our shape before he does any actual operations on it. So, I think this is implementing pretty much exactly what he did, but I’m not totally certain.-
_build_model()[source]¶ Constructs and returns a DeepQaModel (which is a wrapper around a Keras Model) that will take the output of self._get_training_data as input, and produce as output a true/false decision for each input. Note that in the multiple gpu case, this function will be called multiple times for the different GPUs. As such, you should be wary of this function having side effects unrelated to building a computation graph.
The returned model will be used to call model.fit(train_input, train_labels).
-
_instance_type()[source]¶ When reading datasets, what
Instancetype should we create? TheInstanceclass contains code that creates actual numpy arrays, so this instance type determines the inputs that you will get to your model, and the outputs that are used for training.
-
_set_padding_lengths(padding_lengths: typing.Dict[str, int])[source]¶ This is about padding. Any model will have some number of things that need padding in order to make a consistent set of input arrays, like the length of a sentence. This method sets those variables given a dictionary of lengths from a dataset.
Note that you might choose not to update some of these lengths, either because you want to keep the model flexible to allow for dynamic (batch-specific) padding, or because you’ve set a hard limit in the class parameters and don’t want to change it.
-
_set_padding_lengths_from_model()[source]¶ This gets called when loading a saved model. It is analogous to
_set_padding_lengths, but needs to set all of the values set in that method just by inspecting the loaded model. If we didn’t have this, we would not be able to correctly pad data after loading a model.
-
get_instance_sorting_keys() → typing.List[str][source]¶ If we’re using dynamic padding, we want to group the instances by padding length, so that we minimize the amount of padding necessary per batch. This variable sets what exactly gets sorted by. We’ll call
get_padding_lengths()on each instance, pull out these keys, and sort by them in the order specified. You’ll want to override this in your model class if you have more complex models.The default implementation is to sort first by
num_sentence_words, then bynum_word_characters(if applicable).
-
get_padding_lengths() → typing.Dict[str, int][source]¶ This is about padding. Any solver will have some number of things that need padding in order to make consistently-sized data arrays, like the length of a sentence. This method returns a dictionary of all of those things, mapping a length key to an int.
If any of the entries in this dictionary is
None, the padding code will calculate a padding length from the data itself. This could either be a good idea or a bad idea - if you have outliers in your data, you could be wasting a whole lot of memory and computation time if you pad the whole dataset to the size of the outlier. On the other hand, if you do batch-specific padding, this can save you a whole lot of time, if you group batches by similar lengths.Here we return the lengths that are applicable to encoding words and sentences. If you have additional padding dimensions, call super().get_padding_lengths() and then update the dictionary.
-
get_padding_memory_scaling(padding_lengths: typing.Dict[str, int]) → int[source]¶ This method is for computing adaptive batch sizes. We assume that memory usage is a function that looks like this:
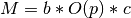 , where
, where 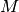 is the memory
usage,
is the memory
usage, 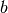 is the batch size,
is the batch size,  is some constant that depends on how much GPU
memory you have and various model hyperparameters, and
is some constant that depends on how much GPU
memory you have and various model hyperparameters, and 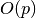 is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set
is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set 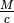 using the
using the
adaptive_memory_usage_constantparameter inDataGenerator. The model (this method) specifies, so we can solve for the batch size . The more
specific you get in specifying in this function, the better a job we can do in
optimizing memory usage.Parameters: padding_lengths: Dict[str, int]
Dictionary containing padding lengths, mapping keys like
num_sentence_wordsto ints. This method computes a function of these ints.Returns: O(p): int
The big-O complexity of the model, evaluated with the specific ints given in
padding_lengthsdictionary.
-
GatedAttentionReader¶
-
class
deep_qa.models.reading_comprehension.gated_attention_reader.GatedAttentionReader(params: deep_qa.common.params.Params)[source]¶ Bases:
deep_qa.training.text_trainer.TextTrainerThis TextTrainer implements the Gated Attention Reader model described in “Gated-Attention Readers for Text Comprehension” by Dhingra et. al 2016. It encodes the document with a variable number of gated attention layers, and then encodes the query. It takes the dot product of these two final encodings to generate an attention over the words in the document, and it then selects the option with the highest summed or mean weight as the answer.
Parameters: multiword_option_mode: str, optional (default=”mean”)
Describes how to calculate the probability of options that contain multiple words. If “mean”, the probability of the option is taken to be the mean of the probabilities of its constituent words. If “sum”, the probability of the option is taken to be the sum of the probabilities of its constituent words.
num_gated_attention_layers: int, optional (default=3)
The number of gated attention layers to pass the document embedding through. Must be at least 1.
cloze_token: str, optional (default=None)
If not None, the string that represents the cloze token in a cloze question. Used to calculate the attention over the document, as the model does it differently for cloze vs non-cloze datasets.
gating_function: str, optional (default=”*”)
The gating function to use in the Gated Attention layer.
"*"is for elementwise multiplication,"+"is for elementwise addition, and"|"is for concatenation.gated_attention_dropout: float, optional (default=0.3)
The proportion of units to drop out after each gated attention layer.
qd_common_feature: boolean, optional (default=True)
Whether to use the question-document common word feature. This feature simply indicates, for each word in the document, whether it appears in the query and has been shown to improve reading comprehension performance.
-
_build_model()[source]¶ The basic outline here is that we’ll pass the questions and the document / passage (think of this as a collection of possible answer choices) into a word embedding layer.
-
_set_padding_lengths(padding_lengths: typing.Dict[str, int])[source]¶ Set the padding lengths of the model.
-
_set_padding_lengths_from_model()[source]¶ This gets called when loading a saved model. It is analogous to
_set_padding_lengths, but needs to set all of the values set in that method just by inspecting the loaded model. If we didn’t have this, we would not be able to correctly pad data after loading a model.
-