TextTrainer¶
-
class
deep_qa.training.text_trainer.TextTrainer(params: deep_qa.common.params.Params)[source]¶ This is a Trainer that deals with word sequences as its fundamental data type (any TextDataset or TextInstance subtype is fine). That means we have to deal with padding, with converting words (or characters) to indices, and encoding word sequences. This class adds methods on top of Trainer to deal with all of that stuff.
This class has five kinds of methods:
- protected methods that are overriden from
Trainer, and which you shouldn’t need to worry about - utility methods for building models, intended for use by subclasses
- abstract methods that determine a few key points of behavior in concrete subclasses (e.g., what your input data type is)
- model-specific methods that you might have to override, depending on what your model looks like - similar to (3), but simple models don’t need to override these
- private methods that you shouldn’t need to worry about
There are two main ways you’re intended to interact with this class, then: by calling the utility methods when building your model, and by customizing the behavior of your concrete model by using the parameters to this class.
Parameters: embeddings : Dict[str, Any], optional (default=50 dim word embeddings, 8 dim character
embeddings, 0.5 dropout on both)
These parameters specify the kind of embeddings to use for words, character, tags, or whatever you want to embed. This dictionary behaves similarly to the
encoderandseq2seq_encoderparameter dictionaries. Valid keys aredimension,dropout,pretrained_file,fine_tune, andproject. The value fordimensionis anintspecifying the dimensionality of the embedding (default 50 for words, 8 for characters);dropoutis a float, specifying the amount of dropout to use on the embedding layer (default0.5);pretrained_fileis a (string) path to a glove-formatted file containing pre-trained embeddings;fine_tuneis a boolean specifying whether the pretrained embeddings should be trainable (defaultFalse); andprojectis a boolean specifying whether to add a projection layer after the embedding layer (only really useful in conjunction with pre-trained embeddings, to get them into a lower-dimensional space; defaultFalse).data_generator: Dict[str, Any], optional (default=None)
If not
None, we will pass these parameters to aDataGeneratorobject to create data batches, instead of creating one big array for all of our training data. SeeDataGeneratorfor the available options here. Note that in order to take full advantage of the capabilities of aDataGenerator, you should make sure your model correctly implements_set_padding_lengths(),get_padding_lengths(),get_padding_memory_scaling(), andget_instance_sorting_keys(). Also note that some of the thingsDataGeneratordoes can change the behavior of your learning algorithm, so you should think carefully about how exactly you want batches to be structured before you choose these parameters.num_sentence_words: int, optional (default=None)
Upper limit on length of word sequences in the training data. Ignored during testing (we use the value set at training time, either from this parameter or from a loaded model). If this is not set, we’ll calculate a max length from the data.
num_word_characters: int, optional (default=None)
Upper limit on length of words in the training data. Only applicable for “words and characters” text encoding.
tokenizer: Dict[str, Any], optional (default={})
Which tokenizer to use for
TextInstances. See :mod:deep_qa.data.tokenizers.tokenizerfor more information.encoder: Dict[str, Dict[str, Any]], optional (default={‘default’: {}})
These parameters specify the kind of encoder used to encode any word sequence input. An encoder takes a sequence of vectors and returns a single vector.
If given, this must be a dict, where each key is a name that can be used for encoders in the model, and the value corresponding to the key is a set of parameters that will be passed on to the constructor of the encoder. We will use the “type” key in this dict (which must match one of the keys in encoders) to determine the type of the encoder, then pass the remaining args to the encoder constructor.
Hint: Use
"lstm"or"cnn"for sentences,"treelstm"for logical forms, and"bow"for either.encoder_fallback_behavior: string, optional (default=”crash”)
Determines the behavior when an encoder is asked for by name, but you have not given parameters for an encoder with that name. See
_get_encoderfor more information.seq2seq_encoder: Dict[str, Dict[str, Any]], optional (default={‘default’: {‘encoder_params’: {}, ‘wrapper_params: {}}})
Like
encoder, except seq2seq encoders return a sequence of vectors instead of a single vector (the difference between our “encoders” and “seq2seq encoders” is the difference in Keras betweenLSTM()andLSTM(return_sequences=True)).seq2seq_encoder_fallback_behavior: string, optional (default=”crash”)
Determines the behavior when a seq2seq encoder is asked for by name, but you have not given parameters for an encoder with that name. See
_get_seq2seq_encoderfor more information.- protected methods that are overriden from
Utility methods¶
These methods are intended for use by subclasses, mostly in your _build_model implementation.
-
TextTrainer._get_sentence_shape(sentence_length: int = None) → typing.Tuple[int][source]¶ Returns a tuple specifying the shape of a tensor representing a sentence. This is not necessarily just (self.num_sentence_words,), because different text_encodings lead to different tensor shapes. If you have an input that is a sequence of words, you need to call this to get the shape to pass to an
Inputlayer. If you don’t, your model won’t work correctly for all tokenizers.
-
TextTrainer._embed_input(input_layer: keras.engine.topology.Layer, embedding_suffix: str = '')[source]¶ This function embeds a word sequence input, using an embedding defined by
embedding_suffix. You should call this function in your_build_modelmethod any time you want to convert word indices into word embeddings. Note that if this is used in conjunction with_get_sentence_shape, we will do the correct thing for whateverTokenizeryou use. The actual input to this might be words and characters, and we might actually do a concatenation of a word embedding and a character-level encoder. All of this is handled transparently to your concrete model subclass, if you use the API correctly, calling_get_sentence_shape()to get the shape for yourInputlayer, and passing that input layer into this_embed_input()method.We need to take the input Layer here, instead of just returning a Layer that you can use as you wish, because we might have to apply several layers to the input, depending on the parameters you specified for embedding things. So we return, essentially,
embedding(input_layer).The input layer can have arbitrary shape, as long as it ends with a word sequence. For example, you could pass in a single sentence, a set of sentences, or a set of sets of sentences, and we will handle them correctly.
Internally, we will create a dictionary mapping embedding names to embedding layers, so if you have several things you want to embed with the same embedding layer, be sure you use the same name each time (or just don’t pass a name, which accomplishes the same thing). If for some reason you want to have different embeddings for different inputs, use a different name for the embedding.
In this function, we pass the work off to self.tokenizer, which might need to do some additional processing to actually give you a word embedding (e.g., if your text encoder uses both words and characters, we need to run the character encoder and concatenate the result with a word embedding).
Note that the
embedding_suffixparameter is a suffix to whatever name the tokenizer will give to the embeddings it creates. Typically, the tokenizer will use the namewords, though it could also usecharacters, or something else. So if you pass_Aforembedding_suffix, you will end up with actual embedding names likewords_Aandcharacters_A. These are the keys you need to specify in your parameter file, for embedding sizes etc. When constructing actualEmbeddinglayers, we will further append the string_embedding, so the layer would be namedwords_A_embedding.
-
TextTrainer._get_encoder(name='default', fallback_behavior: str = None)[source]¶ This method is intended to be used in your
_build_modelimplementation, any time you want to convert a sequence of vectors into a single vector. The encodernamecorresponds to entries in theencoderparameter passed to the constructor of this object, allowing you to customize the kind and behavior of the encoder just through parameters.A sentence encoder takes as input a sequence of word embeddings, and returns as output a single vector encoding the sentence. This is typically either a simple RNN or an LSTM, but could be more complex, if the “sentence” is actually a logical form.
Parameters: name : str, optional (default=”default”)
The name of the encoder. Multiple calls to
_get_encoderusing the same name will return the same encoder. To get parameters for creating the encoder, we look inself.encoder_params, which is specified by theencoderparameter inself.__init__. Ifnameis not a key inself.encoder_params, the behavior is defined by thefallback_behaviorparameter.fallback_behavior : str, optional (default=None)
Determines what to do when
nameis not a key inself.encoder_params. If you passNone(the default), we will useself.encoder_fallback_behavior, specified by theencoder_fallback_behaviorparameter toself.__init__. There are three options:"crash": raise an error. This is the default forself.encoder_fallback_behavior. The intention is to help you find bugs - if you specify a particular encoder name inself._build_modelwithout giving a fallback behavior, you probably wanted to use a particular set of parameters, so we crash if they are not provided."use default params": In this case, we return a new encoder created withself.encoder_params["default"]."use default encoder": In this case, we reuse the encoder created withself.encoder_params["default"]. This effectively changes thenameparameter to"default"when the givennameis not inself.encoder_params.
-
TextTrainer._get_seq2seq_encoder(name='default', fallback_behavior: str = None)[source]¶ This method is intended to be used in your
_build_modelimplementation, any time you want to convert a sequence of vectors into another sequence of vector. The encodernamecorresponds to entries in theencoderparameter passed to the constructor of this object, allowing you to customize the kind and behavior of the encoder just through parameters.A seq2seq encoder takes as input a sequence of vectors, and returns as output a sequence of vectors. This method is essentially identical to
_get_encoder, except that it gives an encoder that returns a sequence of vectors instead of a single vector.Parameters: name : str, optional (default=”default”)
The name of the encoder. Multiple calls to
_get_seq2seq_encoderusing the same name will return the same encoder. To get parameters for creating the encoder, we look inself.seq2seq_encoder_params, which is specified by theseq2seq_encoderparameter inself.__init__. Ifnameis not a key inself.seq2seq_encoder_params, the behavior is defined by thefallback_behaviorparameter.fallback_behavior : str, optional (default=None)
Determines what to do when
nameis not a key inself.seq2seq_encoder_params. If you passNone(the default), we will useself.seq2seq_encoder_fallback_behavior, specified by theseq2seq_encoder_fallback_behaviorparameter toself.__init__. There are three options:"crash": raise an error. This is the default forself.seq2seq_encoder_fallback_behavior. The intention is to help you find bugs - if you specify a particular encoder name inself._build_modelwithout giving a fallback behavior, you probably wanted to use a particular set of parameters, so we crash if they are not provided."use default params": In this case, we return a new encoder created withself.seq2seq_encoder_params["default"]."use default encoder": In this case, we reuse the encoder created withself.seq2seq_encoder_params["default"]. This effectively changes thenameparameter to"default"when the givennameis not inself.seq2seq_encoder_params.
-
TextTrainer._set_text_lengths_from_model_input(input_slice)[source]¶ Given an input slice (a tuple) from a model representing the max length of the sentences and the max length of each words, set the padding max lengths. This gets called when loading a model, and is necessary to get padding correct when using loaded models. Subclasses need to call this in their
_set_padding_lengths_from_modelmethod.Parameters: input_slice : tuple
A slice from a concrete model class that represents an input word sequence. The tuple must be of length one or two, and the first dimension should correspond to the length of the sentences while the second dimension (if provided) should correspond to the max length of the words in each sentence.
Abstract methods¶
You must implement these methods in your model (along with
_build_model()). The simplest concrete TextTrainer
implementations only have four methods: __init__, _instance_type (typically one line),
_set_padding_lengths_from_model (also typically one line, for simple models), and
_build_model. See
TrueFalseModel and
SimpleTagger for examples.
-
TextTrainer._instance_type() → deep_qa.data.instances.instance.Instance[source]¶ When reading datasets, what
Instancetype should we create? TheInstanceclass contains code that creates actual numpy arrays, so this instance type determines the inputs that you will get to your model, and the outputs that are used for training.
-
TextTrainer._set_padding_lengths_from_model()[source]¶ This gets called when loading a saved model. It is analogous to
_set_padding_lengths, but needs to set all of the values set in that method just by inspecting the loaded model. If we didn’t have this, we would not be able to correctly pad data after loading a model.
Semi-abstract methods¶
You’ll likely need to override these methods, if you have anything more complex than a single sentence as input.
-
TextTrainer.get_padding_lengths() → typing.Dict[str, int][source]¶ This is about padding. Any solver will have some number of things that need padding in order to make consistently-sized data arrays, like the length of a sentence. This method returns a dictionary of all of those things, mapping a length key to an int.
If any of the entries in this dictionary is
None, the padding code will calculate a padding length from the data itself. This could either be a good idea or a bad idea - if you have outliers in your data, you could be wasting a whole lot of memory and computation time if you pad the whole dataset to the size of the outlier. On the other hand, if you do batch-specific padding, this can save you a whole lot of time, if you group batches by similar lengths.Here we return the lengths that are applicable to encoding words and sentences. If you have additional padding dimensions, call super().get_padding_lengths() and then update the dictionary.
-
TextTrainer.get_instance_sorting_keys() → typing.List[str][source]¶ If we’re using dynamic padding, we want to group the instances by padding length, so that we minimize the amount of padding necessary per batch. This variable sets what exactly gets sorted by. We’ll call
get_padding_lengths()on each instance, pull out these keys, and sort by them in the order specified. You’ll want to override this in your model class if you have more complex models.The default implementation is to sort first by
num_sentence_words, then bynum_word_characters(if applicable).
-
TextTrainer.get_padding_memory_scaling(padding_lengths: typing.Dict[str, int]) → int[source]¶ This method is for computing adaptive batch sizes. We assume that memory usage is a function that looks like this:
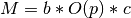 , where
, where 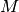 is the memory
usage,
is the memory
usage, 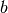 is the batch size,
is the batch size,  is some constant that depends on how much GPU
memory you have and various model hyperparameters, and
is some constant that depends on how much GPU
memory you have and various model hyperparameters, and 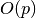 is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set
is a function outlining
how memory usage asymptotically varies with the padding lengths. Our approach will be to
let the user effectively set 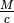 using the
using the
adaptive_memory_usage_constantparameter inDataGenerator. The model (this method) specifies, so we can solve for the batch size . The more
specific you get in specifying in this function, the better a job we can do in
optimizing memory usage.Parameters: padding_lengths: Dict[str, int]
Dictionary containing padding lengths, mapping keys like
num_sentence_wordsto ints. This method computes a function of these ints.Returns: O(p): int
The big-O complexity of the model, evaluated with the specific ints given in
padding_lengthsdictionary.
-
TextTrainer._set_padding_lengths(dataset_padding_lengths: typing.Dict[str, int])[source]¶ This is about padding. Any model will have some number of things that need padding in order to make a consistent set of input arrays, like the length of a sentence. This method sets those variables given a dictionary of lengths from a dataset.
Note that you might choose not to update some of these lengths, either because you want to keep the model flexible to allow for dynamic (batch-specific) padding, or because you’ve set a hard limit in the class parameters and don’t want to change it.
Overridden Trainer methods¶
You probably don’t need to override these, except for probably _get_custom_objects. The rest
of them you shouldn’t need to worry about at all (except to call them, if they are part of the
external Trainer API), but we document them here for completeness.
-
TextTrainer.create_data_arrays(dataset: deep_qa.data.datasets.dataset.IndexedDataset, batch_size: int = None)[source]¶ Takes a raw dataset and converts it into training inputs and labels that can be used to either train a model or make predictions. Depending on parameters passed to the constructor of this
Trainer, this could either return two actual array objects, or a single generator that generates batches of two array objects.Parameters: dataset: Dataset
A
Datasetof the same format as read byload_dataset_from_files()(we will call this directly with the output from that method, in fact)batch_size: int, optional (default = None)
The batch size with which the dataset should be created. If this is None, the default self.batch_size will be used.
Returns: input_arrays: numpy.array or Tuple[numpy.array]
label_arrays: numpy.array, Tuple[numpy.array], or None
generator: a Python generator returning Tuple[input_arrays, label_arrays]
If this is returned, it is the only return value. We either return a
Tuple[input_arrays, label_arrays], or this generator.
-
TextTrainer.load_dataset_from_files(files: typing.List[str])[source]¶ This method assumes you have a TextDataset that can be read from a single file. If you have something more complicated, you’ll need to override this method (though, a solver that has background information could call this method, then do additional processing on the rest of the list, for instance).
-
TextTrainer.score_dataset(dataset: deep_qa.data.datasets.dataset.TextDataset)[source]¶ See the superclass docs (
Trainer.score_dataset()) for usage info. Just a note here that we do not use data generators for this method, even if you’ve said elsewhere that you want to use them, so that we can easily return the labels for the data. This means that we’ll do whole-dataset padding, and this could be slow. We could probably fix this, but it’s good enough for now.
-
TextTrainer.set_model_state_from_dataset(dataset: deep_qa.data.datasets.dataset.TextDataset)[source]¶ Given a raw
Datasetobject, set whatever model state is necessary. The most obvious use case for this is for computing a vocabulary inTextTrainer. Note that this is not anIndexedDataset, and you should not make it one. Useset_model_state_from_indexed_dataset()for setting state that depends on the data having already been indexed; otherwise you’ll duplicate the work of doing the indexing.
-
TextTrainer.set_model_state_from_indexed_dataset(dataset: deep_qa.data.datasets.dataset.IndexedDataset)[source]¶ Given an
IndexedDataset, set whatever model state is necessary. This is typically stuff around padding.
-
TextTrainer._load_auxiliary_files()[source]¶ Called during model loading. If you have some auxiliary pickled object, such as an object storing the vocabulary of your model, you can load it here.
-
TextTrainer._overall_debug_output(output_dict: typing.Dict[str, <built-in function array>]) → str[source]¶ We’ll do something different here: if “embedding” is in output_dict, we’ll output the embedding matrix at the top of the debug file. Note that this could be _huge_ - you should only do this for debugging on very simple datasets.
-
TextTrainer._save_auxiliary_files()[source]¶ Called after training. If you have some auxiliary object, such as an object storing the vocabulary of your model, you can save it here. The model config is saved by default.
-
TextTrainer._set_params_from_model()[source]¶ Called after a model is loaded, this lets you update member variables that contain model parameters, like max sentence length, that are not stored as weights in the model object. This is necessary if you want to process a new data instance to be compatible with the model for prediction, for instance.
-
TextTrainer._uses_data_generators()[source]¶ Training models with Keras requires a different API if you produce data in batches uses a generator or if you just provide one big numpy array with all of your data, which Keras has to split into batches. This method tells us which Keras API we should use. If your model class produces data using a generator, return
Truehere; otherwise, returnFalse. The default implementation just returnsFalse.